Testen von Microservices - Warum mehr Tests nicht immer besser sind


Das Testen von Software ist die Grundlage für hochwertige Software. Ohne ein gutes Testkonzept leidet die Qualität - gleichzeitig kann übermäßiges Testen den Entwicklungsprozess deutlich verlängern. Ein gutes Testkonzept muss daher den Spagat zwischen notwendiger Risikominimierung und Effizienz meistern. Besonders bei verteilten Architekturen wie Microservices und MACH (Microservices, API-first, Cloud-native, Headless) ist das herausfordernd.
Mit Microservices verändert sich nicht nur die Systemarchitektur, sondern die ökonomische Struktur der IT-Organisation:
- Services werden kleiner
- Teams werden autonomer
- Deployments erfolgen häufiger
- Schnittstellen vermehren sich.
Damit steigt die Komplexität nicht linear, sondern exponentiell.
Während ein umfangreicher Systemtest am Ende des Release-Zyklus in monolithischen Systemen oft ausreichend war, so führt dies in Microservice-Landschaften zu massiven Ineffizienzen: jede zusätzliche Service-Interaktion erhöht potenzielle Fehlerpfade.
Die intuitive Reaktion vieler Organisationen lautet:
- „Dann testen wir eben mehr“
- Mehr Integrationstests
- Mehr End-to-End-Tests
- Mehr Regression.
Das Ergebnis:
- Pipeline-Laufzeiten steigen
- Analysezeiten steigen
- Koordinationskosten steigen
- Release-Frequenz sinkt.
Das Problem ist nicht zu wenig Absicherung sondern eine fehlkalibrierte Testverteilung.
Denn die Testverteilung bzw. das Testkonzept beeinflusst viele Faktoren der Produktentwicklung: Je länger die Laufzeit der Tests sind, umso länger ist die Time-To-Market und somit auch die Deplyoment-Frequenz. Dadurch kann aber das Incident-Risiko reduziert werden. In Abhängigkeit in der Ausgestaltung der Tests können Koordinationskosten steigen oder sinken.
In der Praxis begegnet man jedoch häufig Konzepten, die entweder maximale Risikominimierung mit langen Laufzeiten verfolgen oder zu wenig absichern. Dieser Artikel zeigt, wie eine Teststrategie diesen Balanceakt meistert und praxistauglich umgesetzt werden kann. Zur praktischen Anwendung endet jedes Kapitel mit einer kurzen Checkliste.
Unit-Tests
Unit-Tests sind die Basis eines stabilen Testkonzepts. Es sollte darauf geachtet werden, dass wirklich die kleinstmögliche Einheit getestet wird. Das kann eine Methode im klassischen Sinn sein oder zum Beispiel eine AWS‑Lambda‑Funktion. Wichtig ist, dass dies in einer isolierten Umgebung geschieht und die Dauer eines einzelnen Tests deutlich unter einer Sekunde bleibt.
Unit-Tests bilden das Fundament und machen in der Regel den größten Anteil aus. Wenn bereits ein Unit-Test deutlich länger läuft, verzögert sich die gesamte Phase und damit die Zeit, bis eine Änderung produktiv geht.
Der große Vorteil von Unit-Tests: Sie zeigen eindeutig, wo ein Fehler liegt. Schlägt ein Test fehl, befindet sich der Fehler aufgrund der Isolierung innerhalb der Einheit und aufwendige Analysen entfallen.
Aus meiner Erfahrung sind gute Unit-Tests die Grundlage für erfolgreiche Projekte: Fehler werden früh erkannt, und ihre Ursachen lassen sich ohne großen Aufwand eingrenzen. Das bedeutet aber nicht automatisch, dass 100 % Testabdeckung immer sinnvoll sind. Eine starr verfolgte 100-%-Quote, etwa mit Tools wie JaCoCo, kann die Testqualität sogar senken. Am Ende wird oft nur geprüft, ob die 100 % erreicht sind und nicht, ob wirklich alle relevanten Pfade sinnvoll abgedeckt sind. Insbesondere bei Java-Lambda-Ausdrücken erkennt JaCoCo Stand heute nicht alle Pfade zuverlässig und markiert Code fälschlich als abgedeckt. Zudem verdrängt diese simple Metrik häufig die wichtige Diskussion darüber, welche Codebereiche kritisch sind. Alles wird gleichbehandelt und kritische Passagen erhalten dann womöglich zu wenig Aufmerksamkeit.
Checkliste Unit Tests:
- Werden ausschließlich isolierte Units getestet?
- Ist die Laufzeit eines jeden einzelnen Tests unter einer 1 Sekunde?
- Werden alle Pfade bei kritischen Codebereichen getestet?
Integrationstests
Auf den Unit-Tests bauen Integrationstests auf. Wie der Name bereits sagt, wird hier das Zusammenwirken verschiedener Komponenten getestet. Die Komponenten selbst können sehr unterschiedlich sein: das Schreiben in eine reale Datenbank oder das Lesen und Schreiben von Nachrichten über einen Message-Broker.
Hier sind ausschließlich Integrationstests innerhalb eines Microservices gemeint. Denn auch in einem Microservice können mehrere Komponenten existieren, in welchem die Zusammenarbeit essenziell für den Microservice ist.
Aus meinen Projekten habe ich gelernt: Integrationstests werden im Team gut akzeptiert, wenn sie stabil sind, nur bei echten Fehlern fehlschlagen und das Zeitbudget der Build-Pipeline nicht sprengen. Um dies zu gewährleisten, muss die Testumgebung stabil und deterministisch sein. Wichtig ist außerdem, bewusst festzulegen, welche Integrationen getestet werden sollen. Je nach Größe des Projekts lohnt es sich, das explizit zu diskutieren.
Checkliste Integrationstests:
- Ist der Scope für die Tests klar definiert?
- Ist die Testumgebung stabil und deterministisch?
- Wird das Zeitbudget für die Integrationstests eingehalten?
Contract-Tests
In einer Microservice- oder MACH-Architektur kommunizieren zahlreiche Komponenten miteinander. Entweder über klassische REST-Schnittstellen und/oder asynchron über Message-Broker. Die ausgetauschten Daten folgen einem definierten Schema, damit Sender und Empfänger mit dem Format umgehen können. Diese Definition ist der „Vertrag“ zwischen beiden Seiten. Jede Verletzung dieses Vertrags kann zu Fehlern führen.
Meiner Erfahrung nach sind Vertragsverletzungen eine der häufigsten Fehlerursachen in verteilten Systemen. Sie treten meist unbewusst oder aus Unwissen darüber auf, dass ein bestimmtes Feld für einen Empfänger wichtig ist.
Contract-Tests helfen, das zu vermeiden. Sie prüfen auf Sender- wie auf Empfängerseite, ob der vereinbarte Vertrag eingehalten wird. Änderungen am Schema lassen Tests gezielt fehlschlagen - es geht hier nicht um Funktionalität im engeren Sinn, sondern ausschließlich um die Vertragstreue. Ein Beispiel-Tool für Contract-Tests ist Pact.
Checkliste Contract-Tests:
- Sind Contract-Tests vorhanden?
- Sind Contract-Tests für Empfänger wie Sender implementiert?
End-to-End-Tests
End-to-End-Tests prüfen ein System von Anfang bis Ende und zwar ohne Mocks, Stubs oder ähnliche Hilfsmittel. Es wird mit realen Komponenten getestet. Das heißt: Beim Testen einer API-Schnittstelle müssen nicht nur die API-Komponente selbst, sondern auch alle weiteren beteiligten Systeme vorhanden sein - zum Beispiel Datenbank, andere Services wie für Authentifizierung/Autorisierung usw. Dadurch können End-to-End-Tests schnell aufwendig werden.
Während Contract-Tests gezielt den Vertrag prüfen, geht es bei End-to-End-Tests um die tatsächliche Funktion im Zusammenspiel; das Datenschema ist hier zweitrangig.
Neben Schnittstellen werden im End-to-End-Kontext häufig grafische Oberflächen getestet. Mit Tools wie Playwright, Cypress oder dem bekannten Selenium lassen sich solche Tests umsetzen. UI-Tests können jedoch sehr schnell sehr umfangreich werden: In den Tests muss beschrieben werden, welche Buttons zu klicken sind, auf welche Zustandsänderungen gewartet wird usw. Wer solche Tests schon einmal geschrieben hat, weiß, wie kompliziert das werden kann.
Der Hauptgrund für End-to-End-Tests ist, dass sie das größte Vertrauen in das Gesamtsystem schaffen. Besonders für nicht technische Stakeholder wie Product Owner und Business-Analysten sind diese Tests oft sehr wichtig: End-to-End-Tests weisen nach, dass ein Feature im Zusammenspiel aller Komponenten funktioniert und ohne Bedenken veröffentlicht werden kann. Alle vorherigen Testarten zeigen nur, dass Teilbereiche funktionieren und nicht, ob das Gesamtsystem stimmig ist. Wie eingangs erwähnt, sind diese Tests deshalb bei nicht technischen Mitarbeitenden beliebt.
Allerdings haben End-to-End-Tests einige grundsätzliche Nachteile. Zum einen sind sie, insbesondere bei UI-Tests, sehr anfällig: Kleinste Änderungen an der Oberfläche oder Netzwerkstörungen können zu Fehlschlägen führen, obwohl kein echter Fehler vorliegt. Häufen sich solche False Positives, wird die Pipeline in der Praxis oft einfach neu gestartet. Erst wenn Tests wiederholt fehlschlagen, schaut man genauer hin.
Zum anderen dauern UI-Tests vergleichsweise lange. Während frühere Teststufen meist in Millisekunden oder Sekunden erledigt sind, kann ein etwas umfangreicher End-to-End-Test Minuten dauern. Liegen mehrere davon vor, kann dieser Pipeline-Schritt schnell 10 Minuten und mehr beanspruchen. Wird die Pipeline aufgrund instabiler Tests dann erneut gestartet, verlängert sich die Time-to-Production erheblich. Gerade in verteilten Systemen möchte man Änderungen schnell live bringen.
Ein weiterer Punkt: Schlägt ein End-to-End-Test fehl, ist die Ursache selten sofort erkennbar, sondern sie muss analysiert werden, was je nach Grund sehr aufwendig sein kann. Bei Unit-Tests ist die Ursache im Vergleich meist klarer eingrenzbar.
Trotzdem sollten End-to-End-Tests nicht pauschal entfallen. Denn der Vertrauensaspekt ist nicht zu unterschätzen. Wenn diese Tests erfolgreich sind, ist sichergestellt, dass die Anwendung funktioniert. Dieses Vertrauen können die vorherigen Teststufen nur in Maßen liefern.
Aus den genannten Nachteilen ergeben sich aus meiner Sicht zwei Handlungsempfehlungen:
- Gemeinsam mit den Stakeholdern die Funktionen definieren, die den Kern der Plattform ausmachen und nur für diese End-to-End-Tests schreiben. Diese Auswahl sollte regelmäßig hinterfragt und gegebenenfalls Tests auch wieder entfernt werden.
- Konsequent auf Stabilität hinarbeiten: Instabile Tests erzeugen kein Vertrauen und ihre Ergebnisse werden ignoriert. Dies kostet nur Ressourcen und bietet keinen Mehrwert.
Checkliste End-to-End-Tests:
- Werden ausschließlich Kernfunktionen getestet?
- Wird das Zeitbudget für die End-To-End-Tests eingehalten?
- Sind die End-To-End-Tests stabil?
Manuelle Tests
Bisher ging es nur um automatisierte Tests. Auch manuelles Testen kann aber einen großen Mehrwert bieten. Es wird oft weggelassen, weil es als ineffizient gilt und die Annahme vorherrscht, dass automatisierte Tests alles abdecken.
Manuelle Tests sind kein Bestandteil der Pipeline und können losgelöst von Deployments erfolgen. Sowohl das Testsystem als auch das Produktivsystem können als Testumgebung dienen.
Auch bei hoher automatisierter Testabdeckung kann es sinnvoll sein, eine Anwendung manuell zu prüfen, insbesondere bei neuen Funktionen. Voraussetzung ist ein grundlegendes Verständnis der Anwendung. Dann können Testende neue Funktionen durchklicken und gezielt versuchen, Fehler zu provozieren: Dialoge abbrechen, Fenstergrößen ändern, Sonderfälle ausprobieren usw. Der Fantasie sind kaum Grenzen gesetzt. Wichtig ist dabei, dass es klar geregelt ist, welche Personen die Anwendung manuellen Testen und dass dieser Prozess in den normalen Arbeitstag eingebunden ist. Dies kann entweder eine gesonderte QA-Abteilung sein oder die Entwickler selbst.
Manuelles Testen ist definitiv zeitaufwändig, und bei gefundenen Fehlern muss die Ursache ermittelt werden. Dennoch sollte darauf nicht verzichtet werden: Zum einen erhöht es das Vertrauen in die Anwendung, zum anderen werden versteckte Fehler oft früher entdeckt. Außerdem verlässt man sich nicht ausschließlich auf die Rückmeldungen der Nutzenden: Manche Nutzergruppen sind sehr fehlertolerant und akzeptieren mitunter, dass bestimmte Funktionen nicht funktionieren. Bis der Fehler auffällt, vergeht dann viel Zeit.
Spannend wird, wie KI künftig exploratives manuelles Testen unterstützen oder teilweise übernehmen kann. Hier liegt aus meiner Sicht großes Potenzial: KI-Agenten könnten Anwendungen gezielt testen und Menschen entlasten.
Checkliste Manuelle Tests:
- Existiert ein Prozess fürs manuelle Testen?
- Sind die Zuständigkeiten fürs manuelle Testen geregelt?
- Werden die Ergebnisse strukturiert ins Team zurückgegeben?
Fehlerkostenkurve
In vielen Teams wird über Testabdeckung, Testarten und Testautomatisierung gesprochen, aber erstaunlich selten darüber, dass Teststrategie im Kern eine ökonomische Allokationsentscheidung ist: Wo investieren wir wie viel Zeit und Geld in Tests, um die Gesamtkosten von Fehlern zu minimieren?
Genau hier setzt die Fehlerkostenkurve an als strategische Leitplanke für die Testarchitektur an. Denn Fehlerkosten steigen nicht linear, sondern typischerweise exponentiell entlang ihrer Entdeckungsstufe. Der gleiche fachliche oder technische Fehler verursacht ganz unterschiedliche Aufwände in Abhängigkeit, wann der Fehler gefunden wird.
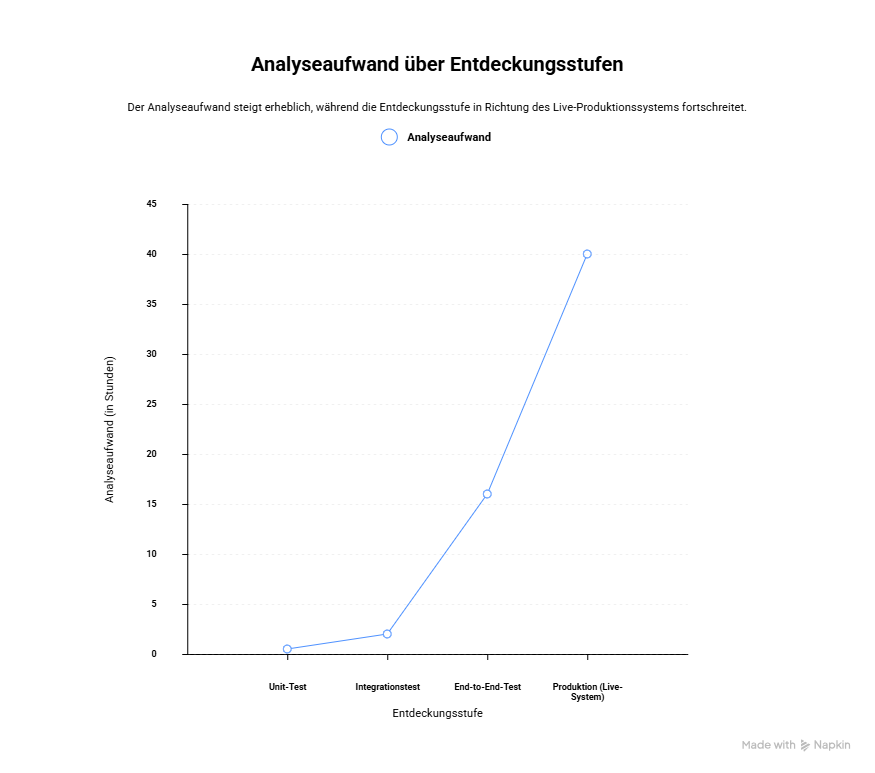
In der nachfolgenden Tabelle sind die einzelnen Teststufen aufgelistet mit ihren Merkmalen wie sie die Testkosten beeinflussen.
Eine strategisch ausgerichtete Testarchitektur verschiebt Fehlererkennung systematisch nach vorne, weil sich die Investition auf den frühen Ebenen rechnet. Jeder früh erkannte Fehler vermeidet ein Vielfaches an Kosten, die entstehen würden, wenn derselbe Fehler erst im Systemtest oder in der Produktion auffällt.
Trotzdem sollte dies nicht als Dogma verstanden werden, sondern als Orientierungshilfe für Prioritäten. Es sollte nicht alles aus Prinzip nach vorne geschoben werden, sondern nur dort, wo es sinnvoll ist. In bestimmten Situationen genügen Monitoring in Kombination mit einem schnellen Incident-Handling anstatt ausführlicher Tests zu schreiben.
Fazit
Das Testen von Microservices und MACH-Architekturen ist kein Selbstzweck, sondern das Sicherheitsnetz für schnelle Release-Zyklen. Hierzu gehören nicht nur technische Entscheidungen, sondern vor allem auch organisatorische bzw. projektspezifische Entscheidungen: Nicht alles muss getestet werden, sondern die richtigen Dinge und das kann sich von Projekt zu Projekt unterscheiden. Wie gezeigt, liegt der Schlüssel zum Erfolg nicht in der bloßen Menge an Tests, sondern in ihrer gezielten Verteilung:
- Unit-Tests sorgen für ein schnelles, stabiles Fundament.
- Integration- und Contract-Tests sichern die Kommunikation in verteilten Systemen ab, ohne die Pipeline zu verlangsamen.
- End-to-End-Tests schaffen das nötige Vertrauen für die Business-Stakeholder, sollten aber aufgrund ihrer Komplexität sparsam und fokussiert eingesetzt werden.
- Manuelle Tests bleiben das Korrektiv für das Unvorhersehbare: Ein stimmiges Testkonzept meistert den Spagat zwischen Qualität und Geschwindigkeit, indem es Redundanzen vermeidet und Fehler dort abfängt, wo sie am günstigsten zu beheben sind. Natürlich ist die funktionale Absicherung nur eine Seite der Medaille. Für ein vollständiges Bild müssen auch Aspekte wie die Automatisierung in der CI/CD-Pipeline, der Aufbau von Testumgebungen sowie nicht-funktionale Tests (Last- und Sicherheitstests) betrachtet werden. Dies sind Themen, die wir in zukünftigen Artikeln womöglich weiter vertiefen.
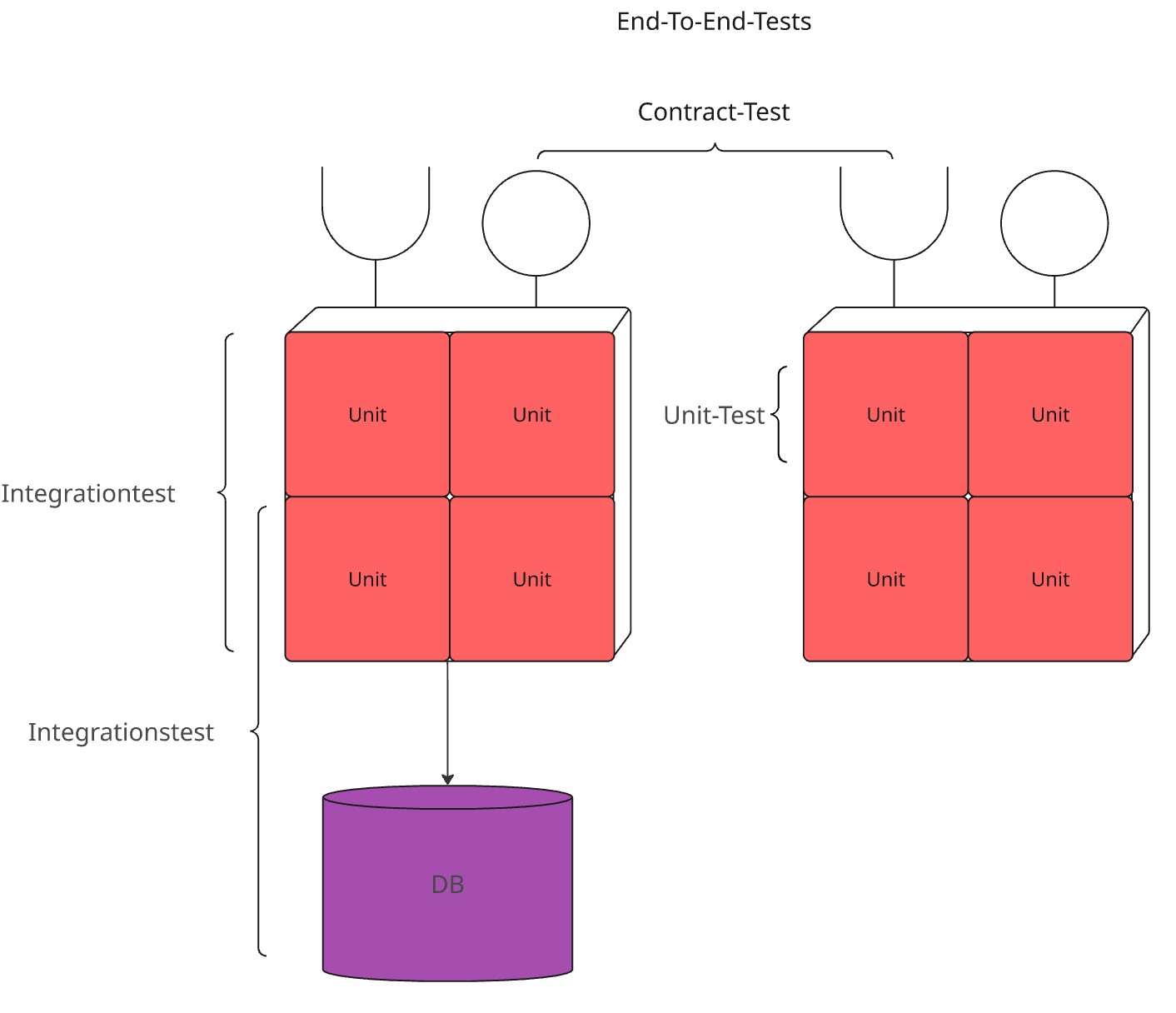
Abbildung 1: Überblick über die verschiedenen Teststufen und die jeweils getesteten Komponenten
Hilfreich ist dabei auch folgende Leitplanken zu definieren:
- Maximale Pipeline-Laufzeit: Festgelegte Dauer, wie lange eine Pipeline von Anfang bis Ende dauern darf. Bei Überschreitung der Zeit müssen entweder Build-Steps optimiert werden oder Tests reduziert werden.
- Minimaler Unit-Test-Anteil: Festgelegtes Minimum an Unit-Tests, die vorhanden sein müssen.
- Verbindliche Contract-Standards: Klare Regeln und Absprache zwischen den Teams über die Einhaltung der Datenformate sowie Dokumentation dieser Formate.
- Null-Toleranz für instabile Tests: Konsequente Löschung von instabilen Tests. Instabile Tests reduzieren nur das Vertrauen in die Tests und somit auch in die Anwendung.
Wichtig ist, dass das Testkonzept auch als ökonomische Allokationsentscheidung verstanden wird und die Fehlerkostenkurve beachtet wird. Denn dann wird aus „mehr Tests bauen“ eine bewusste, begründbare Architekturentscheidung und aus Testen ein zentraler Hebel für die Wirtschaftlichkeit der Systeme.
Nutz die Checklisten als Startpunkt, um Deine aktuelle Strategie zu hinterfragen und Schritt für Schritt zu optimieren oder kontaktiere uns, um mit unseren Experten ins Gespräch zu gehen.